Spatial clustering with BANKSY + pymclustR#
BANKSY mixes each spot’s own expression with a spatially weighted neighbour profile — a single λ trades off cell-typing vs domain segmentation.
This notebook runs the BANKSY spatial embedder on the
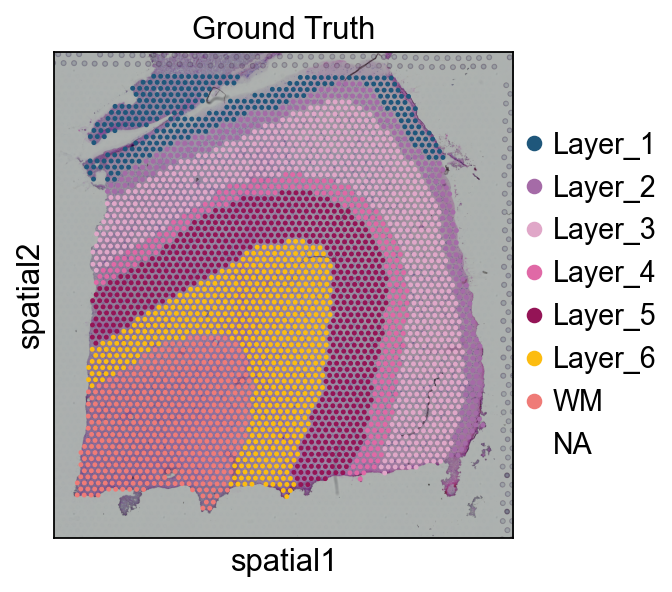
Maynard 151676 dorsolateral prefrontal cortex Visium sample
(3 460 spots × 10 747 genes) and clusters the resulting embedding with
pymclustR, a pure-Python
re-implementation of CRAN mclust (no rpy2 / R dependency).
Pre-processed input lives at
/scratch/users/steorra/analysis/omicverse_dev/omicverse-test/notebooks/data/cluster_svg.h5ad, which is the canonical fixture used in the originalt_cluster_spacetutorial.
0. Load AnnData + Ground Truth#
import omicverse as ov
import scanpy as sc
import pandas as pd, os, anndata as ad
ov.style(font_path='Arial')
# Load the pre-processed AnnData (3460 spots × 10747 genes — the same
# input the original spatial-clustering tutorial was developed against).
DATA_DIR = '/scratch/users/steorra/analysis/omicverse_dev/omicverse-test/data/151676'
H5AD = '/scratch/users/steorra/analysis/omicverse_dev/omicverse-test/notebooks/data/cluster_svg.h5ad'
adata = ad.read_h5ad(H5AD)
truth = pd.read_csv(os.path.join(DATA_DIR, '151676_truth.txt'),
sep='\t', header=None, index_col=0)
truth.columns = ['Ground Truth']
adata.obs['Ground Truth'] = truth['Ground Truth'].reindex(adata.obs_names)
print('shape:', adata.shape, ' annotated:',
adata.obs['Ground Truth'].notna().sum())
adata
🔬 Starting plot initialization...
Using already downloaded Arial font from: /tmp/omicverse_arial.ttf
Registered as: Arial
🧬 Detecting GPU devices…
✅ NVIDIA CUDA GPUs detected: 1
• [CUDA 0] NVIDIA H100 80GB HBM3
Memory: 79.1 GB | Compute: 9.0
____ _ _ __
/ __ \____ ___ (_)___| | / /__ _____________
/ / / / __ `__ \/ / ___/ | / / _ \/ ___/ ___/ _ \
/ /_/ / / / / / / / /__ | |/ / __/ / (__ ) __/
\____/_/ /_/ /_/_/\___/ |___/\___/_/ /____/\___/
🔖 Version: 2.1.2rc1 📚 Tutorials: https://omicverse.readthedocs.io/
✅ plot_set complete.
shape: (3460, 10747) annotated: 3431
AnnData object with n_obs × n_vars = 3460 × 10747
obs: 'in_tissue', 'array_row', 'array_col', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'pct_counts_in_top_50_genes', 'pct_counts_in_top_100_genes', 'pct_counts_in_top_200_genes', 'pct_counts_in_top_500_genes', 'Ground Truth'
var: 'gene_ids', 'feature_types', 'genome', 'n_cells_by_counts', 'mean_counts', 'log1p_mean_counts', 'pct_dropout_by_counts', 'total_counts', 'log1p_total_counts', 'space_variable_features', 'highly_variable'
uns: 'REFERENCE_MANU', 'spatial'
obsm: 'spatial'
layers: 'counts'
sc.pl.spatial(adata, img_key='hires', color=['Ground Truth'])
1. Embed with BANKSY#
BANKSY (Singhal et al., Nat. Genet. 2024) constructs a hybrid feature
matrix that mixes each spot’s own expression with a spatially weighted
neighbour profile. A single tunable mixing parameter λ controls the
trade-off between cell-typing and tissue-domain segmentation.
methods_kwargs = {'Banksy': {
'num_neighbours': 15,
'nbr_weight_decay': 'scaled_gaussian',
'max_m': 1,
'lambda_list': [0.2],
'resolutions': [0.8],
'add_nonspatial': False,
'variance_balance': False,
'match_labels': False,
'filepath': '/tmp/banksy_pymclustR',
}}
# BANKSY internally calls IPython.display.display() on a pandas
# DataFrame whose cells contain Label / AnnData objects — nbformat
# can't JSON-serialise those, so capture both stdout and any rich
# display output while it runs.
from IPython.utils.capture import capture_output
with capture_output(stdout=True, stderr=True, display=True) as _captured:
_ = ov.space.clusters(adata, methods=['Banksy'], methods_kwargs=methods_kwargs)
# Promote BANKSY's chosen embedding under a stable key for downstream cells
banksy_key = next(k for k in adata.obsm.keys() if k.startswith('X_banksy_'))
adata.obsm['X_banksy'] = adata.obsm[banksy_key]
print('BANKSY embedding:', adata.obsm['X_banksy'].shape, ' key:', banksy_key)
BANKSY embedding: (3460, 20) key: X_banksy_scaled_gaussian_pc20_nc0.20_r0.80

2. Cluster with pymclustR (no rpy2 / R needed)#
ov.utils.cluster(adata, use_rep='X_banksy', method='pymclustR',
n_components=10, modelNames='EEE', random_state=42)
adata.obs['pymclustR_BANKSY'] = ov.utils.refine_label(adata, radius=50, key='pymclustR')
adata.obs['pymclustR_BANKSY'] = adata.obs['pymclustR_BANKSY'].astype('category')
finished: found 10 clusters and added
'pymclustR', the cluster labels (adata.obs, categorical)
[model=EEE, loglik=-191946.6819, BIC=-387307.8047]
3. Spatial visualisation#
sc.pl.spatial(adata, color=['pymclustR_BANKSY', 'pymclustR', 'Ground Truth'])
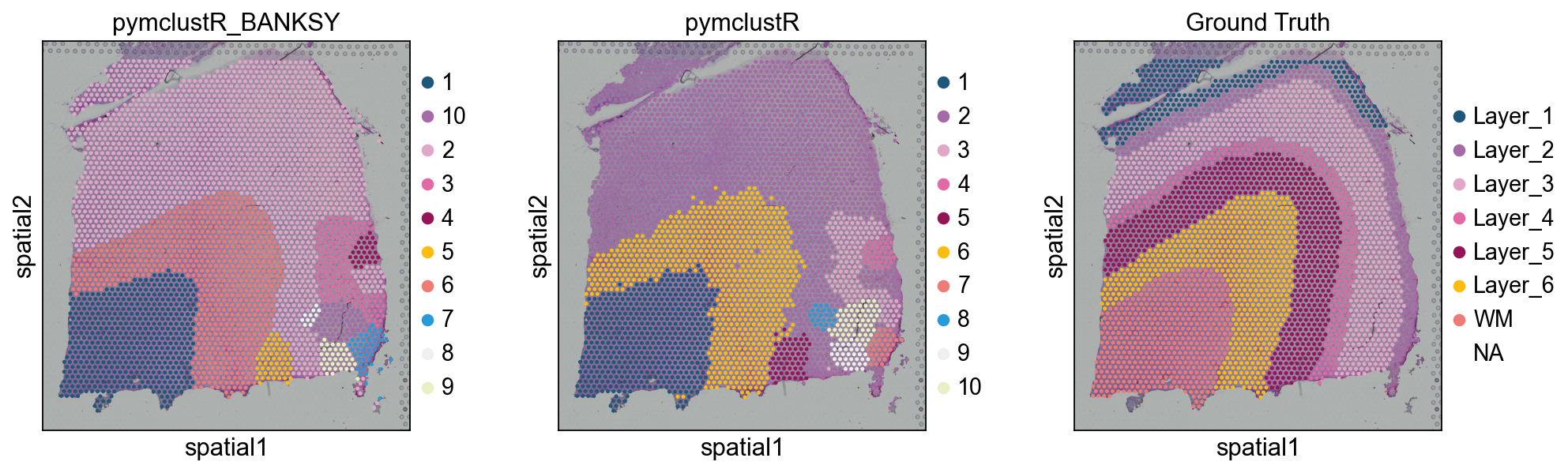
4. ARI vs Maynard ground truth#
from sklearn.metrics.cluster import adjusted_rand_score
obs = adata.obs.dropna(subset=['Ground Truth'])
ari_raw = adjusted_rand_score(obs['pymclustR'], obs['Ground Truth'])
ari_ref = adjusted_rand_score(obs['pymclustR_BANKSY'], obs['Ground Truth'])
print(f'BANKSY + pymclustR (raw): ARI = {ari_raw:.4f}')
print(f'BANKSY + pymclustR (refined): ARI = {ari_ref:.4f}')
BANKSY + pymclustR (raw): ARI = 0.3072
BANKSY + pymclustR (refined): ARI = 0.3068